{kind=link}
{kind=link}
MapReduce 工作机制
MapReduce 擅长处理大数据,其思想就是“分而治之”。
Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reducer负责对map阶段的结果进行汇总。
MapReduce 的整个工作过程如上图所示,它包含如下4个独立的实体: 实体一:客户端,用来提交 MapReduce 作业。 实体二:JobTracker,用来协调作业的运行。 实体三:TaskTracker,用来处理作业划分后的任务,即真正的计算部分。 实体四:HDFS,用来在其它实体间共享作业文件。

MapReduce 的局限
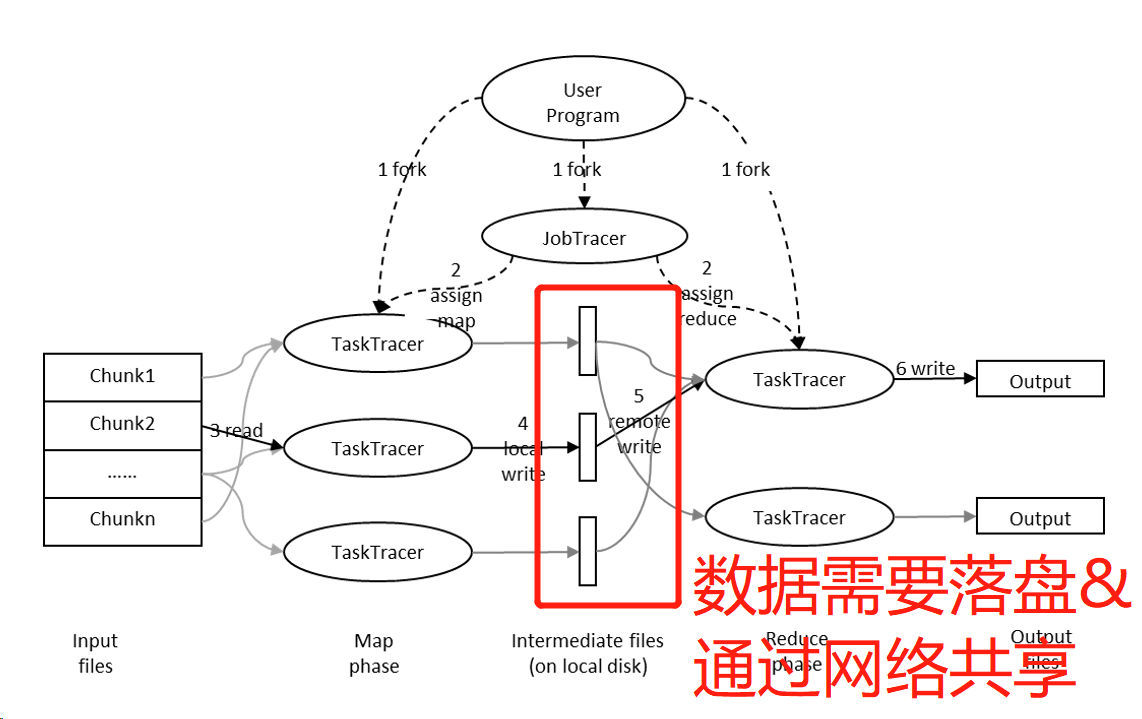
MapReduce 是一个为批量处理而设计的模型,从任务的启动延迟性、中间结果的落盘的特点不难看出,采用这一计算模型的系统,都具有时延较高的特点,在那些对时延非常敏感的系统中不宜采用。也就是说 MapReduce 比较适合那些超大数据量的计算,不适合轻量级计算。
Spark也有延迟,要低延迟的话得用Flink或者SparkStream
- 复习 MapReduce 框架 (@2023-12-13)