{kind=link}
{kind=link}
Deflate 算法
Deflate 是一个同时使用 LZ77 与 Huffman Coding 的算法,这里简单介绍下这两种算法的大致思路:
LZ77
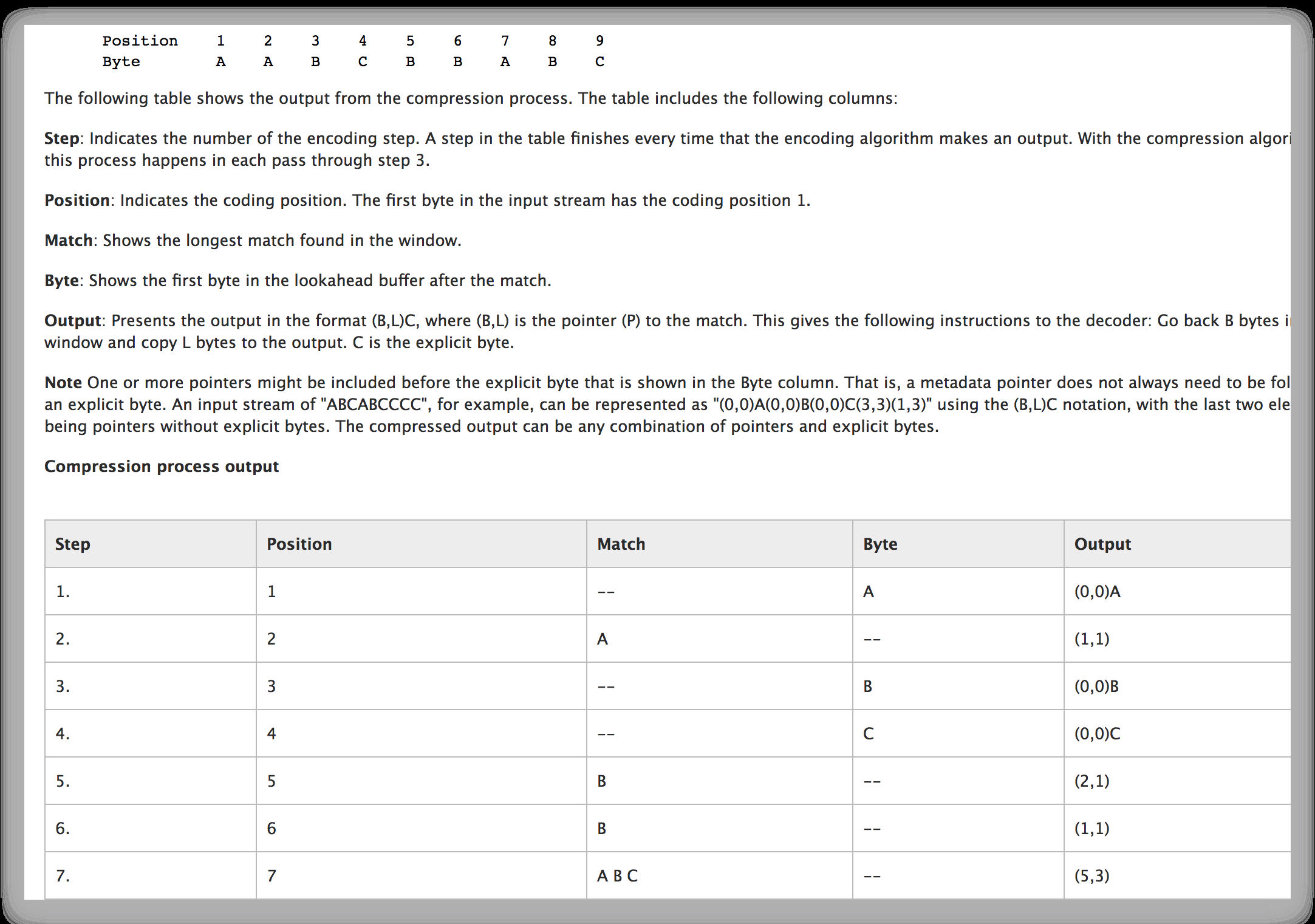
LZ77 的核心思路是如果一个串中有两个重复的串,那么只需要知道第一个串的内容和后面串相对于第一个串起始位置的距离 + 串的长度。
比如: ABCDEFGABCDEFH → ABCDEFG(7,6)H。7 指的是往前第 7 个数开始,6 指的是重复串的长度,ABCDEFG(7,6)H 完全可以表示前面的串,并且是没有二义性的。
LZ77 用 滑动窗口(sliding-window compression)来实现这个算法。具体思路是扫描头从串的头部开始扫描串,在扫描头的前面有一个长度为 N 的滑动窗口。如果发现扫描头处的串和窗口里的 最长匹配串 是相同的,则用(两个串之间的距离,串的长度)来代替后一个重复的串,同时还需要添加一个表示是真实串还是替换后的“串”的字节在前面以方便解压(此串需要在 真实串和替换“串” 之前都有存在)。
Huffman Coding
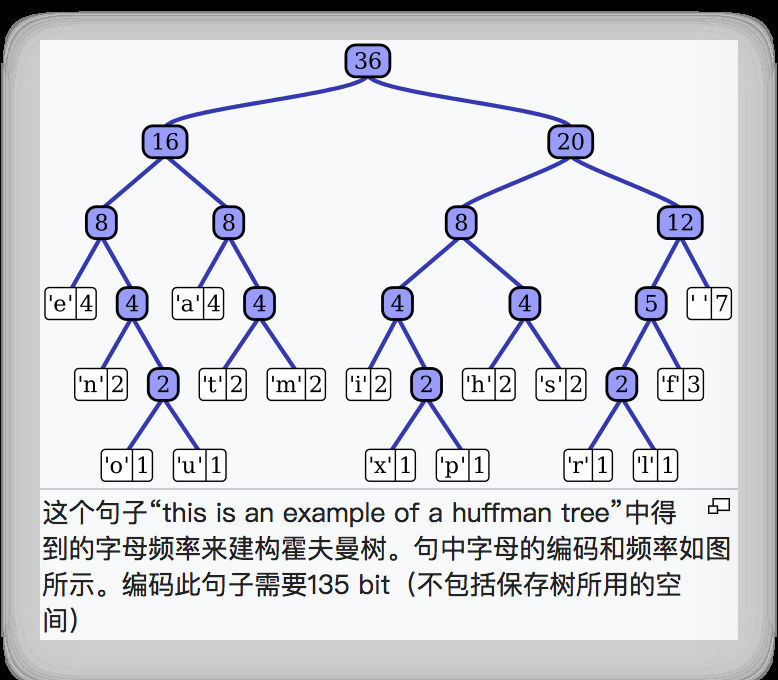
Huffman Coding 是大学课本中一般都会提到的算法。核心思路是通过构造 Huffman Tree 的方式给字符重新编码(核心是避免一个叶子的路径是另外一个叶子路径的前缀),以保证出现频路越高的字符占用的字节越少
应用 - Gzip
基于 HTTP 协议的网络传输中 GZip 经常被使用,Nginx 中也可以使用半行代码开启 GZip
每个压缩数据集都是下面的结构:
| ID1 | ID2 | CM | FLG | MTIME(4字节) | XFL | OS | ---> more
|与|之间是 1 byte,都是大端字节(Big Edian)
-
其中 ID1 和 ID2 分别是 0x1f 和 0x8b,用来标识文件格式是 gzip
-
CM 标识 加密算法,目前 0-7是保留字,8 指的是 deflate 算法
-
FLG 从低地址到高地址分别是 FTEXT、FHCRC、FEXTRA、FNAME、FCOMMENT、reserved、 reserved、reserved,这里每个 bit 被设置了之后有什么意义感兴趣的话可以详细参考 RFC 1952。比较有意思的是 FEXTRA,如果它被设置了表示存在额外的拓展字段。拓展字段的结构如下:
- | SI1 | SI2 | LEN | … LEN bytes of subfield data … |
- SI1、SI2 是对子域的 ID,由 ASCII 码组成。如果你需要使用的话,可以向他的维护者 Jean-Loup Gailly
<gzip@prep.ai.mit.edu>发邮件申请。目前 Apollo file 就有自己的专属 ID
-
MTIME 指的是源文件最近一次修改时间,存的是 Unix 时间戳
-
XFL 是给压缩算法传的一些参数,用来标识如何解压。defalte 算法中 2 表示使用压缩率最高的算法,4 表示使用压缩速度最快的算法
-
OS 标识压缩程序运行的文件系统,以处理 EOF 等的问题
-
more 后面是根据 FLG 的开启情况决定的,可能会有 循环冗余校验码、源文件长度、附加信息等多种其他信息
GZIP 的核心是 Deflate,在 RFC 1951 中被标准化,并且在当时作为 LZW 的替代品有了非常广泛的使用。
Gzip 压缩过程可以简单概括为以下步骤:
- 分析输入数据,找到重复的字节序列。
- 使用 LZ77 算法将重复的字节序列替换为引用。
- 使用哈夫曼编码对数据进行编码,将频率较高的字符用较短的编码表示。
- 将压缩后的数据与一些元数据(如文件信息、压缩算法标识)一起打包形成压缩文件。
应用 - 7z
7z 使用的是 LZMA(Lempel-Ziv-Markov chain Algorithm)压缩算法。LZMA 是一种基于字典的无损压缩算法,它结合了 LZ77 算法和二阶马尔可夫链。
- LZ77 算法:与 Gzip 中使用的 LZ77 算法相同,LZMA 也使用 LZ77 算法来找到重复的字节序列并进行替换。
- 二阶马尔可夫链:LZMA 引入了二阶马尔可夫链来提高压缩效果。二阶马尔可夫链考虑了当前字符与前两个字符的关系,从而更准确地预测下一个字符。
Gzip 和 7z 都是无损压缩算法,它们的压缩原理都是通过找到重复的数据并使用合适的编码方式来减小文件的大小。然而,7z 使用的 LZMA 压缩算法在某些情况下能够提供更高的压缩比,但需要更多的计算资源和时间来进行压缩和解压缩操作。