{kind=link}
{kind=link}
常见的容错策略:
- 故障转移: 如果节点存在多个备用节点,那么出现故障之后,可以快速转移到对应的副本之中。 同时需要设置一个重试的次数上限,比如三次,因为重试也是存在成本的
- 快速失败:故障转移策略的前提是服务是幂等的,如果是非幂等的,那么重试可能就会存在脏数据。比如一些敏感服务,无法判断出错位置,那么就直接失败
- 安全失败:对于一些旁路逻辑,比如日志等,失败了就直接失败,不影响后面计算,即失败了也可以当做正确返回
- 沉默失败:当请求失败之后,一段事件不再分配流量,将错误直接隔离
- 故障恢复:服务失败之后,将失败的消息存入消息队列,系统开始异步重试调用。当然前提也是要求需要存在幂等性
- 并行调用:向多个服务发起调用,以执行成本换取成功概率
- 广播调用:并行调用只要一个成功即可,广播需要全部返回成功,比如刷新分布式缓存
快速失败 - 断路器模式
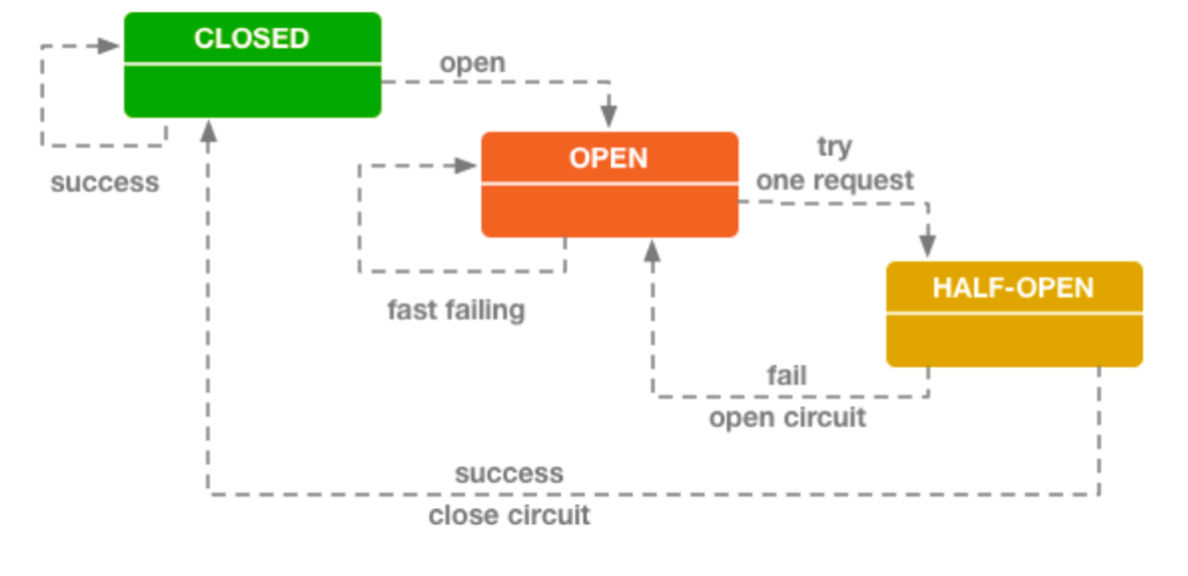
CLOSED:断路器关闭,请求发送给服务提供者
OPEN:开启,不会远程请求,直接返回失败
HALF OPEN:断路器不能一直OPEN ,当执行一段时间之后,需要切换到 HALF OPEN 状态,会再次尝试一次远程调用
沉默失败 - 舱壁隔离模式
为了防止一个服务挂了之后,阻塞超时导致全局性故障,比如线程占用不释放,如果不加以限制,可能就直接撑爆了容器限制
所以这里需要对服务的线程资源做一个限制,比如设置一个单独的线程池去管理服务的线程数量,而不是直接给一个容器最大值
故障转移 和 故障恢复 - 重试模式
对于临时服务的失败,比如网络抖动、临时过载等造成的失败,可以直接重试
注意需要时幂等性的服务才可以重复 (POST一般都不是幂等的,PUT GET 等一般都是幂等的)
重试需要有明确的终止条件:超时终止 和 次数终止
- 复习 服务容错 (@2023-12-02)