{kind=link}
{kind=link}
Fork-Join 概述
Fork/Join 框架通过使用分而治之和工作窃取机制来实现更高程度的并行性。
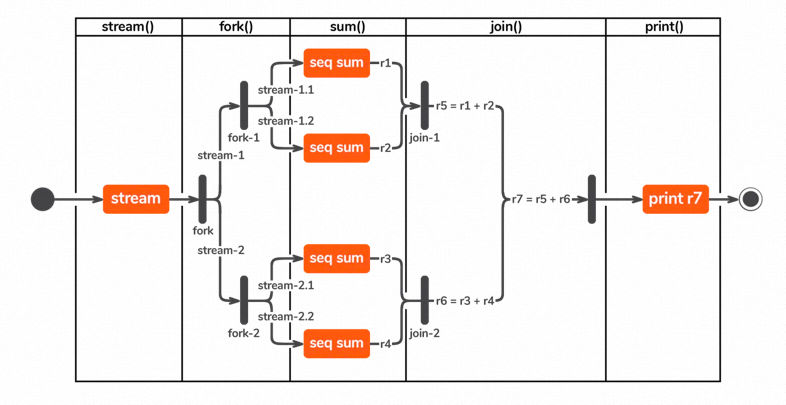
fork/join 池以递归方式划分较大的任务,直到可以按顺序计算子任务而不会进一步分解。在任务完成执行后,它们返回结果,这些结果被连接回来,然后返回最终结果。下图是并行计算0~100000的fork-join示意图。
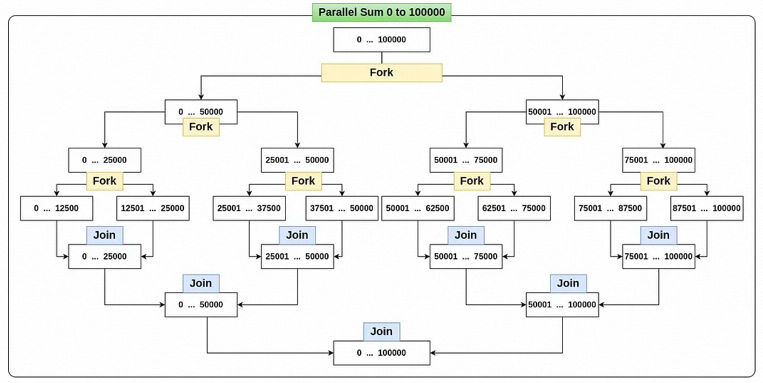
在使用fork-join框架中,需要注意:
- Fork/Join 本身不能分割任务,也不能自行合并结果。需要我们指定一种划分任务和合并结果的方法。
- Fork/Join 框架无法决定一项任务是否可以进一步划分。我们必须指定一种识别它的方法,例如设置一个特定的阈值,当达到该阈值时,将按顺序计算任务。
Fork-Join操作Demo
使用 Fork/Join 框架实现并行算法
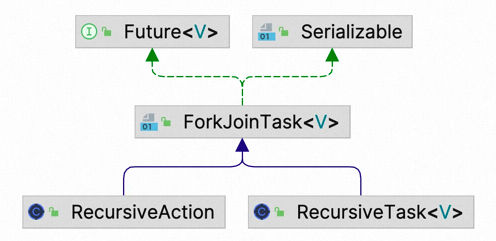
在实践中,使用ForkJoin框架,必须首先创建一个ForkJoinTask任务。它提供在任务中执行fork()和join()操作的机制。通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
- RecursiveAction用于没有返回结果的任务
- RecursiveTask用于有返回结果的任务。
创建任务唯一需要做的是重写compute()方法并实现逻辑。该方法规定了程序Fork、Computation 和 Join 操作的具体位置。
ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池。ForkJoinPool提供了如下两个常用的构造器
// 创建一个包含parallelism个并行线程的ForkJoinPool
public ForkJoinPool(int parallelism)
//以Runtime.getRuntime().availableProcessors()的返回值作为parallelism来创建ForkJoinPool
public ForkJoinPool() :创建ForkJoinPool实例后,可以调用ForkJoinPool的submit(ForkJoinTask task)或者invoke(ForkJoinTask task)来执行指定任务。
完整的一个例子:
public class ParallelSumComputationUsingForkJoin {
private static final int[] LARGE_ARR = largeArr();
private static final int LENGTH = LARGE_ARR.length;
public static void main(String[] args) {
RecursiveSumTask recursiveSumTask = new RecursiveSumTask(0,LENGTH,LARGE_ARR);
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
long start = System.currentTimeMillis();
long sum = forkJoinPool.invoke(recursiveSumTask);
System.out.println("The sum is : "
+ sum
+ ", Time Taken by Parallel(Fork/Join) Execution: "
+ (System.currentTimeMillis() - start) + " millis");
}
private static int[] largeArr() {
return new Random().ints(900000000,10,1000).toArray();
}
static class RecursiveSumTask extends RecursiveTask<Long> {
// 子任务计算的最小范围
private static final int SEQUENTIAL_COMPUTE_QUEUE = 4000;
private final int startIndex;
private final int endIndex;
private final int[] data;
public RecursiveSumTask(int startIndex, int endIndex, int[] data) {
this.startIndex = startIndex;
this.endIndex = endIndex;
this.data = data;
}
@Override
protected Long compute() {
if (SEQUENTIAL_COMPUTE_QUEUE >= (endIndex -startIndex)) {
long sum = 0;
for (int i = startIndex; i <endIndex ; i++) {
sum += data[i];
}
return sum;
}
// 分解任务
int mid = startIndex + (endIndex - startIndex) / 2;
RecursiveSumTask leftTask = new RecursiveSumTask(startIndex,mid,data);
RecursiveSumTask rightTask = new RecursiveSumTask(mid,endIndex,data);
leftTask.fork();
long rightSum = rightTask.compute();
long leftSum = leftTask.join();
return leftSum + rightSum;
}
}
}
让leftSumTask进行fork()操作,这意味着它被添加到工作窃取队列中,在ForkJoinPool队列中的任何线程都可以拾取并执行它。关于工作窃取机制在后文进行详细阐述
Fork-Join 原理
工作窃取机制
深入探讨一下fork和join方法,以及ForkJoinPool背后的工作窃取机制
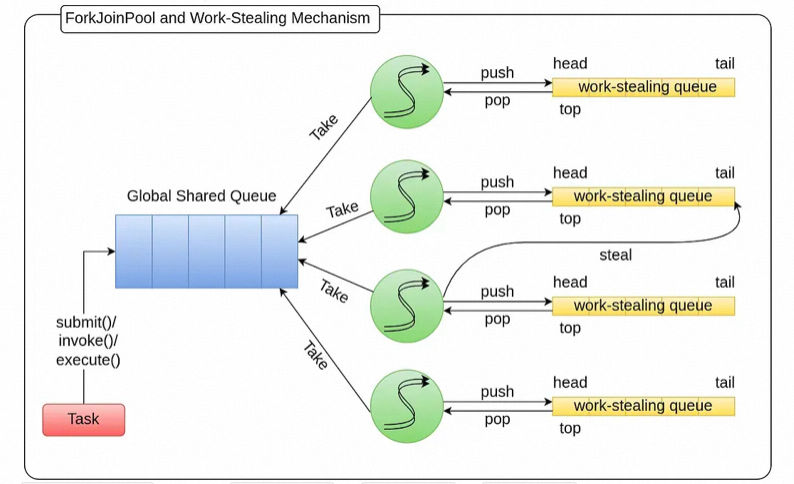
-
ForkJoinTask可以使用execute()、invoke()和submit()来提交任务。
-
ForkJoinPool维护一个全局共享队列,所有工作线程都可以访问。所有提交的任务都会在这个Shared Queue中排队。
-
Pool中有工作线程,每个工作线程都有自己的队列,称为工作窃取队列(该特定工作线程的本地队列)工作线程从共享队列中获取任务,并将它们存储在本地工作窃取队列中。(目标:通过保持所有工作线程始终尽可能繁忙来最大化 CPU 利用率)
-
fork-join 池中的每个工作线程都运行一个循环来检查要执行的任务。这些工作线程为了让自己始终尽可能忙碌,会检查来自多个输入源的任务
-
**全局共享队列:工作线程最初获取任务的地方。
-
**本地工作窃取队列:线程从全局共享队列获取主任务后,工作线程在拆分子任务时,会将这些子任务推送到自己的本地工作窃取队列中。
-
**其他线程的工作窃取队列:这是实际的工作窃取机制出现的地方。线程从其他线程的工作窃取队列中窃取任务。
-
工作线程以 LIFO 顺序访问自己的工作窃取队列,并以 FIFO 顺序访问其他线程的工作窃取队列。
-
工作线程在拆分任务并派生子任务时,将派生的子任务添加到队列的前面。而且取的时候是从队列前面取。
-
如果某个特定线程是空闲的(它自己的队列是空的),那么就可以从其他线程队列的末尾窃取。
-
如何决定从哪个其他线程队列中选择任务?随机。总体广义上,窃取符合FIFO。
为什么这样设计?
- 减少工作线程之间的争用。为了在工作窃取队列上提供轻量级锁定机制。
- 提供更好的Locality of Reference——缓存性能。
- 位于队列末尾的任务较旧(最先添加),代表较大的工作单元,位于队列前面的任务较年轻(最近添加),代表较小的工作单元。如果一个线程在自己的队列上运行,它首先完成较小的任务,然后再完成较大的任务。如果一个线程从其他线程的队列中窃取工作,则需要更大的任务,以便通过进一步拆分来单独解决它。
和 ExecutorService 之间的区别
| Fork/Join Framework | ExecutorService |
|---|---|
| Fork/Join 框架是分而治之算法的实现,中央 ForkJoinPool 执行分支 ForkJoinTasks。 | ExecutorService 是一个 Executor,它提供用于管理异步任务的进度跟踪和终止的方法。 |
| Fork/Join 框架利用了工作窃取算法。 在 Fork/Join 框架中,当一个任务等待它使用联接操作创建的子任务完成时,执行该任务的工作线程会查找另一个尚未执行的任务,并窃取它们以开始执行。 | 与 Fork/Join 框架不同,当任务等待它使用联接操作创建的子任务完成时,执行该等待任务的工作线程不会查找其他任务。 |
| fork-join 非常适合递归问题,其中任务涉及运行子任务,然后处理其结果。 | 如果使用 ExecutorService 解决此类递归问题,则最终会导致线程被捆绑,等待其他线程向它们传递结果。 |
| Fork Join 是 ExecuterService 的实现。主要区别在于,此实现创建了一个 DEQUE 工作线程池。 | Executor 服务创建请求数量的线程,并应用阻塞队列来存储所有剩余的等待任务。 |
并行流
原理
从 Java 8 开始,流的方面也使并行性成为惯用语,在深入了解过Fork-Join框架后,并行流的运转方式也就不再神秘了。用一个简单的示例程序演示并行流的执行过程:
public long sumUsingParallel() {
return LongStream.rangeClosed(1L, 10L)
.parallel()
.peek(this::printThreadName)
.reduce(0L, this::printSum);
}
public void printThreadName(long l) {
String tName = currentThread().getName();
System.out.println(tName + " offers:" + l);
}
public long printSum(long i, long j) {
long sum = i + j;
String tName = currentThread().getName();
System.out.printf(
"%s has: %d; plus: %d; result: %d\n",
tName, i, j, sum
);
return sum;
}调用会触发数字流上的fork-join机制,将流拆分为在四个线程中运行。每个线程都有一个流,每个线程以并行方式运行。
1.确定规模 并行流适用于对大型数据集进行密集计算的场景。如果数据集较小或计算量较小,则串行流可能更合适。并行流的创建和维护涉及到线程调度和数据划分的开销,如果任务过于简单,可能会导致性能下降。
2.合适的数据结构 在使用并行流时,应该选择适合并行处理的数据结构。使用并发集合(如ConcurrentHashMap)可以在并行流中实现更好的性能。
3.数据共享和竞态条件 并行流中的操作是并发执行的,因此需要特别注意数据共享和竞态条件的问题。确保操作是线程安全的,可以使用同步块或并发集合来保护共享数据。
4.避免有状态的操作 在并行流中,应尽量避免有状态的操作,即操作的结果依赖于前面的操作或全局状态。这种操作可能导致竞争和不确定的结果。应使用无状态的操作,如map和filter。
5.调整并行度 默认情况下,并行流使用的线程数是根据可用的处理器核心数来决定的。有时可能需要手动调整并行度以获得更好的性能。
Demo
public class ParallelSumStream {
public static void main(String[] args) {
LongStream.range(1L, 100L)
.parallel()
.peek(ParallelSumStream::printThreadName)
.reduce(ParallelSumStream::printSum);
}
public static void printThreadName(long l) {
String tName = Thread.currentThread().getName();
System.out.println(tName + " offers:" + l);
}
public static long printSum (long i , long j ) {
long sum = i + j;
System.out.printf(
"%s has: %d; plus: %d; result: %d\n",
Thread.currentThread().getName(), i, j, sum
);
return sum;
}
}